Distributed chatbot systems rely on networks of independent components to handle user interactions. These systems scale better than single-server setups but come with challenges like managing service locations, failures, and performance. Service discovery automates how these components find and communicate with each other, ensuring smooth operation even as services start, stop, or move.
Key Takeaways:
-
What is Service Discovery?
It automates how distributed nodes locate and connect, using a service registry - a dynamic "phone book" of active services. -
Common Challenges Solved:
- Scalability: Handles dynamic changes in chatbot instances.
- Fault Tolerance: Redirects traffic from failed nodes.
- Latency: Ensures real-time updates to avoid failed connections.
-
How It Works:
- Service Registry: Tracks active service instances.
- Health Checks: Ensures only healthy nodes handle requests.
-
Discovery Methods:
- Client-Side: The client queries the registry directly (e.g., Netflix Eureka).
- Server-Side: A load balancer handles registry lookups (e.g., AWS ELB).
-
Registration Options:
- Self-Registration: Chatbots register themselves, offering detailed control but requiring more coding.
- Platform-Managed: An external system registers services, simplifying operations but limiting internal state visibility.
Each approach has trade-offs. Choosing the right method depends on your system's architecture, programming languages, and operational goals.
How Service Discovery Works
Service Registry and Resolution
The backbone of service discovery is the service registry - a database that keeps track of the network locations for all active chatbot service instances [1][2]. As Chris Richardson explains:
"A service registry is a database of services, their instances and their locations." [1]
When a chatbot starts up, it registers itself in the registry with its IP address and port. When it shuts down, it deregisters itself [1]. This process is especially important in environments where chatbot instances are frequently created or terminated based on traffic needs.
If a system component needs to connect to another service, it queries the registry using the service's logical name. The registry then provides the location of a healthy instance [1][2]. This system functions seamlessly across various platforms, whether you're working with virtual machines, containers, or serverless setups [2].
Since the registry is such a critical piece of the system, it uses multiple nodes and peer-to-peer management to ensure it remains highly available [1][2]. To guard against temporary registry outages, clients often store a local cache of registry data [1].
This dynamic registry setup works hand-in-hand with health checks to ensure that only active chatbot instances are used to handle traffic.
Health Checks and Service Availability
Health checks play a key role in ensuring that only operational chatbot instances handle traffic. For example, in systems like Netflix Eureka, each instance sends regular heartbeat signals - typically every 30 seconds [8]. If an instance stops sending these signals, the registry automatically removes it from the directory.
Another approach involves active health probing. Here, the registry periodically contacts each instance's /health endpoint. For instance, Spring Cloud Consul performs these checks every 10 seconds. If an instance fails to respond or returns an error, it is flagged as "critical" and removed from the pool of available services [5][7].
HashiCorp highlights the broader goal of this process:
"Service discovery helps you discover, track, and monitor the health of services within a network." [2]
In some systems, like Apache ZooKeeper, ephemeral nodes are used. These nodes automatically delete themselves if a process crashes or disconnects [6]. This automation ensures clients don't waste time trying to connect to instances that are no longer available, reducing failed requests and improving user satisfaction.
What is Service Discovery?
2 Methods of Service Discovery
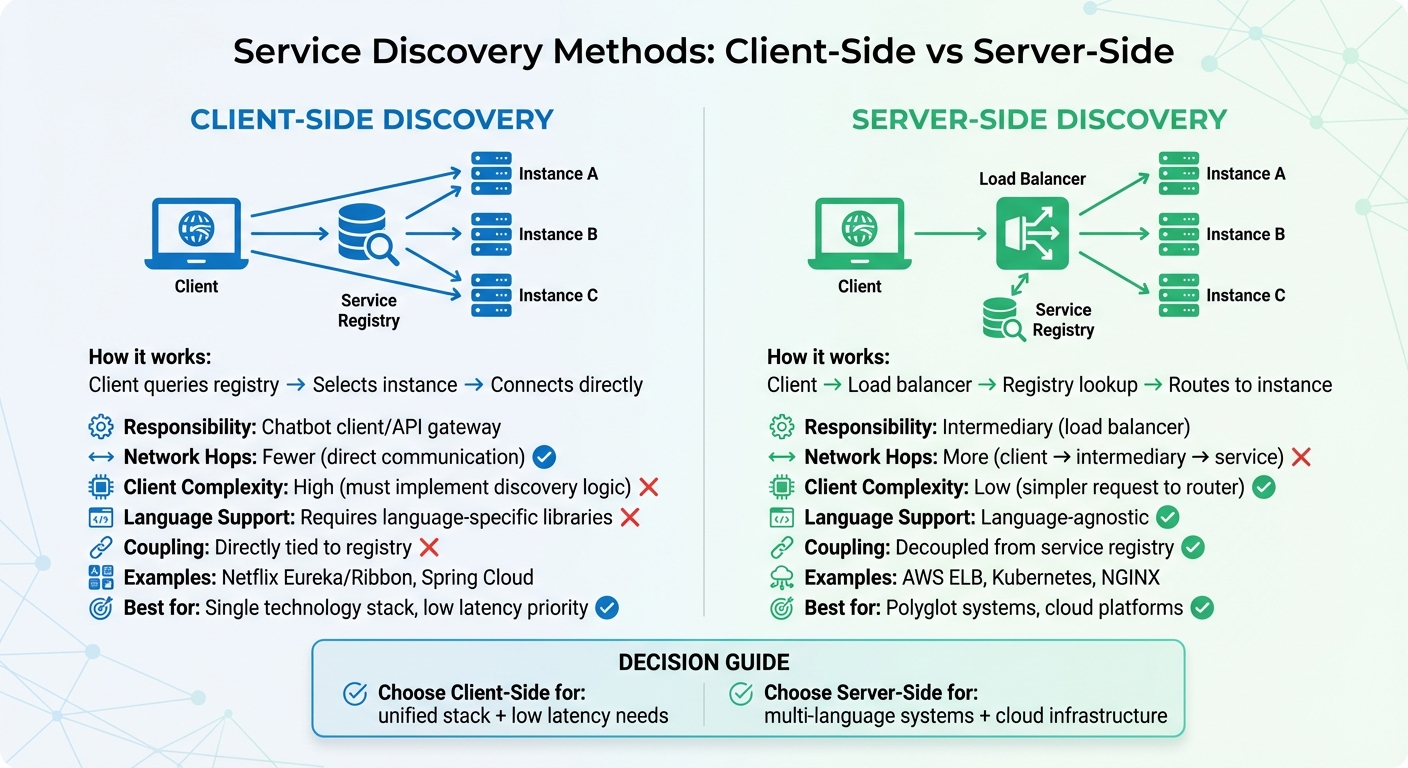
Service Discovery Methods Comparison for Distributed Chatbot Systems
Distributed chatbot systems rely on two main approaches for service discovery: client-side and server-side. Each method has its own way of functioning, along with specific advantages and challenges.
Client-Side Service Discovery
In client-side discovery, the client takes on the responsibility of querying the service registry, choosing a healthy service instance, and connecting directly to it. Essentially, the client embeds the logic for interacting with the service registry. A well-known example of this setup is Netflix's open-source stack: Eureka acts as the service registry, while Ribbon manages HTTP requests by querying Eureka for service locations and routing traffic to available instances. This approach is commonly used in Spring Boot and Spring Cloud environments, especially when running on a unified Java platform.
Chris Richardson, author of Microservices Patterns, highlights a key benefit of this approach:
"Client-side discovery has the benefit of fewer moving parts and network hops compared to Server-side Discovery."
By directly connecting to the service after the initial lookup, this method reduces latency. However, there’s a notable downside: the discovery logic - handling tasks like registration, heartbeats, and resolution - needs to be implemented for each programming language in use. This can complicate maintenance in environments that use multiple languages.
Server-side discovery, on the other hand, centralizes these responsibilities.
Server-Side Service Discovery
Server-side discovery simplifies things for the chatbot client. Instead of managing the registry directly, the client sends its request to a load balancer, which handles the registry lookup and forwards the request to a healthy service instance.
A popular example of this approach is AWS Elastic Load Balancer (ELB). In this setup, chatbot clients send HTTP requests to the ELB, which then distributes the traffic across backend instances or containers. This eliminates the need for clients to know the specific IP addresses of backend services. Similarly, Kubernetes uses built-in Services to provide stable endpoints for routing traffic to healthy pods.
HashiCorp describes the advantage of this method:
"For modern applications, [server-side discovery] is advantageous because developers can make their applications faster and more lightweight by decoupling and centralizing service discovery logic."
This approach simplifies client code and makes it language-agnostic, as the router handles all the complexity. However, it introduces an additional network hop, and the router itself must be highly available to avoid becoming a single point of failure.
Both methods rely on a service registry as a foundation, but they differ in how responsibilities are distributed.
| Feature | Client-Side Discovery | Server-Side Discovery |
|---|---|---|
| Responsibility | Chatbot client/API gateway | Intermediary |
| Network Hops | Fewer (direct communication) | More (client → intermediary → service) |
| Client Complexity | High (must implement discovery logic) | Low (simpler request to the router) |
| Language Support | Requires language-specific libraries | Language-agnostic |
| Coupling | Directly tied to the registry | Decoupled from the service registry |
| Examples | Netflix Eureka/Ribbon, Spring Cloud | AWS ELB, Kubernetes, NGINX |
If your chatbot system uses a single technology stack and prioritizes low latency, client-side discovery is a good fit. On the other hand, server-side discovery works better for polyglot systems or when leveraging cloud platforms with built-in discovery and load balancing features.
Self-Registration vs Platform-Managed Discovery
When it comes to managing chatbot discovery, deciding who handles registration is just as important as the discovery mechanism itself. Should each chatbot instance handle its own registration, or should a centralized platform take care of it? This choice directly impacts how much control you have over your chatbot’s state and the complexity of the code.
Self-Registration by Chatbot Instances
With self-registration, each chatbot instance takes charge of registering itself with the service registry. When the chatbot starts up, it provides its network location (like an IP address and port) and metadata such as version or environment details. Software architect Chris Richardson explains:
"A service instance is responsible for registering itself with the service registry. On startup the service instance registers itself (host and IP address) with the service registry and makes itself available for discovery." [10]
Once registered, the chatbot sends periodic heartbeat signals - about every 30 seconds - to confirm it’s still available [12]. If the registry stops receiving these signals, it assumes the chatbot is offline and may remove it. Additionally, when the chatbot shuts down gracefully, it sends an unregistration request [10][12].
This method offers fine-grained control over service state. For example, a chatbot can report statuses beyond just "UP" or "DOWN", like "STARTING" or "OUT_OF_SERVICE" [10]. However, it comes with a trade-off: the chatbot’s code becomes tightly linked to the service registry [10]. In polyglot systems (where multiple programming languages are used), this can make maintenance tricky, as you’ll need to implement registration logic for each language. Another challenge is handling unexpected crashes - if a chatbot fails without unregistering, the registry may end up with stale entries [10].
Platform-Managed Registration
In platform-managed registration, a separate infrastructure component - often called a registrar - takes care of registering chatbot instances [1][11]. When a new instance starts, the registrar detects it and handles the registration automatically.
This approach simplifies things by decoupling the chatbot code from the registry. Instances can focus on processing requests without worrying about registration details [4]. This is particularly helpful in polyglot systems, as it eliminates the need for language-specific client libraries [9]. Many cloud platforms, like AWS and Kubernetes, offer this functionality as part of their infrastructure, making it easier to integrate without building custom tools [4][11].
However, this method does have some limitations. Platform-managed systems often rely on external health checks rather than self-reported statuses, so you lose some visibility into the chatbot’s internal state [10]. Additionally, there’s an extra network hop involved, as requests typically pass through a router or load balancer before reaching the chatbot instance [4]. That said, this approach aligns well with efforts to simplify client-side operations.
Comparison: Self-Registration vs Platform-Managed
Both strategies work with service registry mechanisms, but they offer different benefits and trade-offs depending on your system’s needs.
| Feature | Self-Registration | Platform-Managed |
|---|---|---|
| Responsibility | The chatbot instance itself | An external registrar or orchestrator |
| Coupling | High; service code must interact with the registry | Low; service is unaware of the registry |
| State Awareness | High; supports complex status reporting | Limited; uses external health checks |
| Language Support | Requires logic for each language | Language-agnostic |
| Failure Handling | May leave stale entries on crashes | Automatically detects crashes |
| Infrastructure | Needs a separate registry (e.g., Eureka) | Often built into platforms (e.g., Kubernetes) |
If your chatbot system relies on a single programming language and requires detailed control over its state, self-registration might be the better option. On the other hand, for multi-language setups or deployments on cloud platforms with built-in discovery tools, platform-managed registration keeps things simpler and reduces the operational burden on your team.
Conclusion
Service discovery plays a crucial role in scaling distributed chatbot systems. Without it, managing manual IP updates would create significant disruptions in the system’s functionality [3]. As Kay James from Gravitee aptly states:
"Service discovery is arguably the first piece of infrastructure you should adopt when moving to microservices." [3]
By implementing a real-time service catalog, your system can automatically route traffic to healthy instances, scale horizontally without requiring manual adjustments, and evenly distribute user requests across chatbot instances. This ensures no single node becomes overwhelmed, while users consistently connect to a functioning service. The variety of mechanisms available allows for solutions tailored to specific system needs.
Choosing the right discovery method depends on your system’s architecture and programming language requirements. For example, in a polyglot environment with multiple programming languages, server-side discovery combined with platform-managed registration can simplify operations. On the other hand, a single-language setup might benefit more from self-registration, offering tighter control over service state.
To ensure success, focus on implementing robust health checks, maintaining a highly available service registry, and using caching to minimize network lookups. These strategies transform service discovery into a resilient component that seamlessly adapts to infrastructure changes. This lets your team concentrate on enhancing conversational AI, while addressing the challenges of scalability, fault tolerance, and consistency - especially during periods of high traffic.
At ChatSpark, these principles guide us in building distributed chatbot systems that are scalable, reliable, and capable of delivering consistent, high-quality customer interactions 24/7.
FAQs
What’s the difference between client-side and server-side service discovery in distributed chatbot systems?
Client-side and server-side service discovery handle the process of locating and connecting to service instances differently.
In client-side discovery, the client takes charge of finding service instances. It directly queries a service registry to identify available options and then communicates with the chosen instance. This approach gives the client more control but also means it has to handle the discovery logic independently.
In contrast, server-side discovery shifts this responsibility. The client sends its request to a router or load balancer, which then consults the service registry and directs the request to the appropriate service instance. This setup simplifies the client's role, making it especially useful in environments with complex routing or when scaling is a priority.
How do health checks make sure chatbot systems stay reliable?
Health checks play a key role in keeping chatbot systems dependable by continuously monitoring the performance of individual instances. These checks determine if a chatbot instance is operating correctly and capable of managing incoming requests.
When an instance doesn't pass a health check, it's automatically removed from handling requests. This ensures that only properly functioning instances are in use, helping to maintain consistent performance and avoid service interruptions.
What are the benefits of using platform-managed registration in distributed chatbot systems?
Platform-managed registration streamlines the way services are added or removed within distributed chatbot systems. By automating the process of service registration and deregistration, it ensures that every service remains discoverable and properly listed in the system's registry.
This method boosts system reliability by minimizing the chances of outdated or missing service entries. It also supports scalability, allowing new services to be integrated effortlessly - no manual steps required - making it simple to keep up with increasing demands.